library(tidyverse)
library(r4pde)
theme_set(theme_r4pde()) # set global theme14 Gradient models
Similar to the disease progress curves, models can be fitted empirically to observed disease gradient curves and provide insights into the mechanisms of inoculum dispersal and deposition, the source of inoculum, and the physical processes underlying dispersal.
When modeling disease gradients, the distance is represented by \(x\), a continuous variable which can be expressed by various units (cm, m, km, etc). The gradient models, similar to the population dynamics models (disease progress) are of the deterministic type. The difference is that, for disease progress curves, disease intensity tends to increase with increasing time, while in disease gradients the disease intensity tends to decrease with increasing distance from the source of inoculum. Two models are most commonly fitted to data on disease gradients. More details about these models can be obtained it this tutorial.
14.1 Exponential model
The exponential model is also known as Kiyosawa & Shiyomi model. The differential of the exponential model is given by
\(\frac{dy}{dx}\) = \(-b_{E}.y\) ,
where \(b_{E}\) is the exponential form of the rate of decline and \(y\) is the disease intensity. This model suggests that \(y\) (any disease intensity) is greater close to the source of inoculum, or at the distance zero. The integral form of the model is given by
\(y = a . e^{-b.x}\) ,
where \(a\) is the disease intensity at the distance zero and \(b\) is the rate of decline, in this case negative because disease intensity decreases with the increase of the distance from inoculum source. Let’s make a plot for two disease gradients of varying parameters for this model.
First we need to load essential packages for programming, customizing the outputs and defining a global ggplot theme.
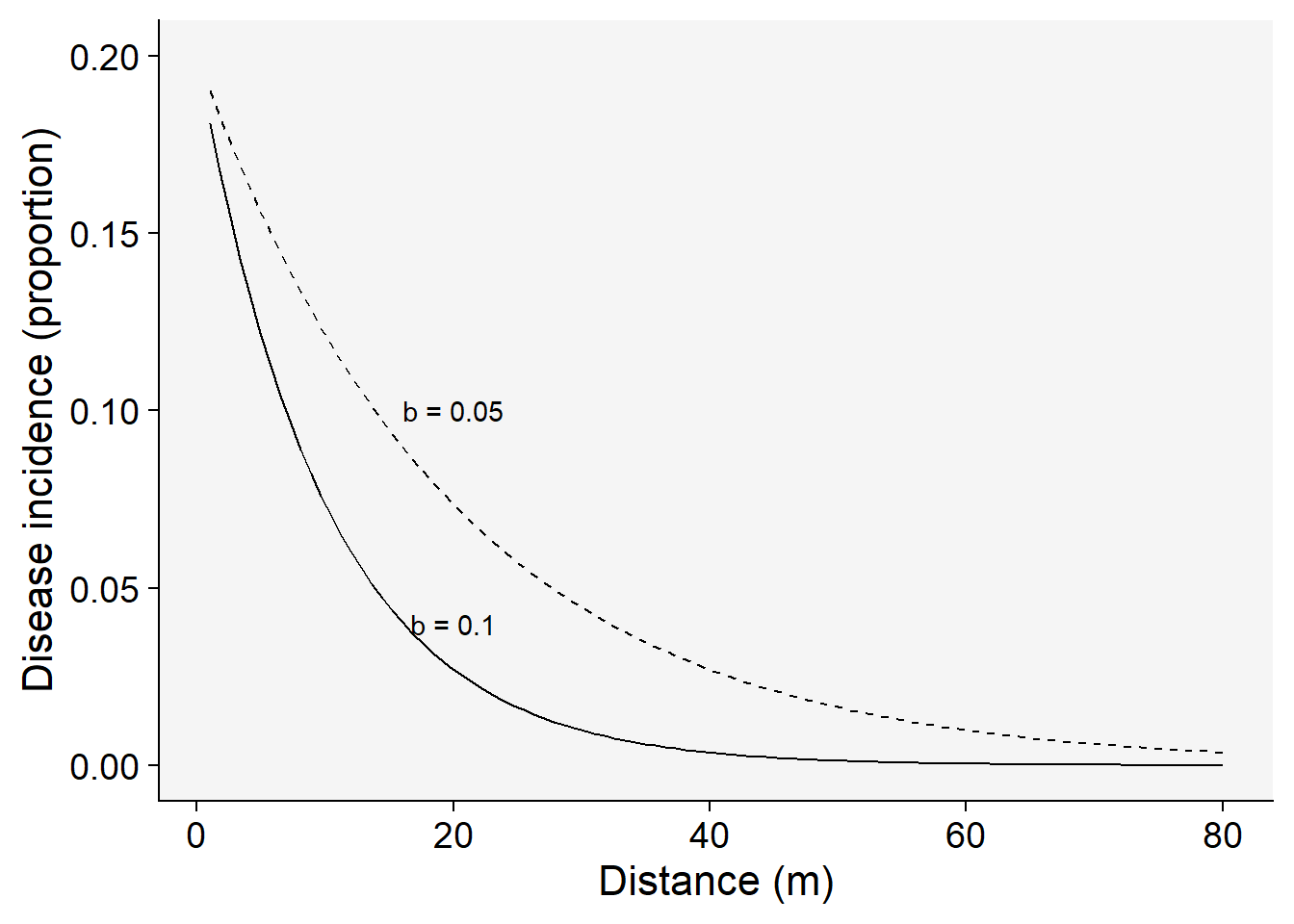
Set the parameters for the exponential model with two rates and the same inoculum level at the source:
a1 <- 0.2 # y at distance zero for gradient 1
a2 <- 0.2 # y at distance zero for gradient 2
b1 <- 0.1 # decline rate for gradient 1
b2 <- 0.05 # decline rate for gradient 2
max1 <- 80 # maximum distance for gradient 1
max2 <- 80 # maximum distance for gradient 2
dat <- data.frame(x = seq(1:max1), y = seq(0:a1))The following code allows to visualize the model predictions.
dat |>
ggplot(aes(x, y)) +
theme_r4pde()+
stat_function(fun = function(x) a1 * exp(-b1 * x), linetype = 1) +
stat_function(fun = function(x) a2 * exp(-b2 * x), linetype = 2) +
ylim(0, a1) +
annotate("text", x = 20, y = 0.04, label = "b = 0.1") +
annotate("text", x = 20, y = 0.10, label = "b = 0.05") +
labs(x = "Distance (m)", y = "Disease incidence (proportion)"
)
14.2 Power law model
Also known as the modified Gregory’s model (Gregory was a pioneer in the use this model to describe plant disease gradients). In the power law model, \(Y\) is proportional to the power of the distance, and is given by:
\(Y = a_{P}.x - b_{P}\)
where \(a_{P}\) and \(b_{P}\) are the two parameters of the power law model. They differ from the exponential because as closer to \(x\) is to zero, \(Y\) is indefinitely large (not meaningful biologically). However, the model can still be useful because it produces realistic values at any distance \(x\) away from the source. The values of the \(a_{P}\) parameter should be interpreted in accord to the scale of \(x\), whether in centimeters or meters. If the distance between the source and the first measure away from the source is 0.5m, it is so more appropriate to record the distance in cm than in m or km.
Once \(y\) at the distance zero from the source is undefined when using the power law model, this is usually modified by the addition of a positive constant \(C\) in \(x\):
\(Y = a_{P}.(x + C) - b_{P}\)
For this reason, the model is named as the modified power law. Here, the constant \(C\) is of the same unit of \(x\). At the distance zero, the positive constant is a term that express the size of the inoculum source. In other words, the \(a\) parameter is a theoretical value of \(Y\) at the distance \(1-C\) from the center of the inoculum source.
Let’s plot two gradients with two rate parameters for the modified power law model:
C <- 0.5
a1 <- 0.2 # y at zero distance for gradient 1
a2 <- 0.2 # y at zero distance for gradient 2
b1 <- 0.5 # decline rate for gradient 1
b2 <- 0.7 # decline rate for gradient 2
max1 <- 80 # maximum distance for gradient 1
max2 <- 80 # maximum distance for gradient 2
dat2 <- data.frame(x = seq(1:max1), y = seq(0:a1))dat2 |>
ggplot(aes(x, y)) +
theme_r4pde()+
stat_function(fun = function(x) a1 * ((x + C)^-b1), linetype = 1) +
stat_function(fun = function(x) a2 * ((x + C)^-b2), linetype = 2) +
ylim(0, a1 - 0.02) +
annotate("text", x = 20, y = 0.03, label = "b = 0.1") +
annotate("text", x = 20, y = 0.06, label = "b = 0.05") +
labs(x = "Distance (m)", y = "Disease incidence")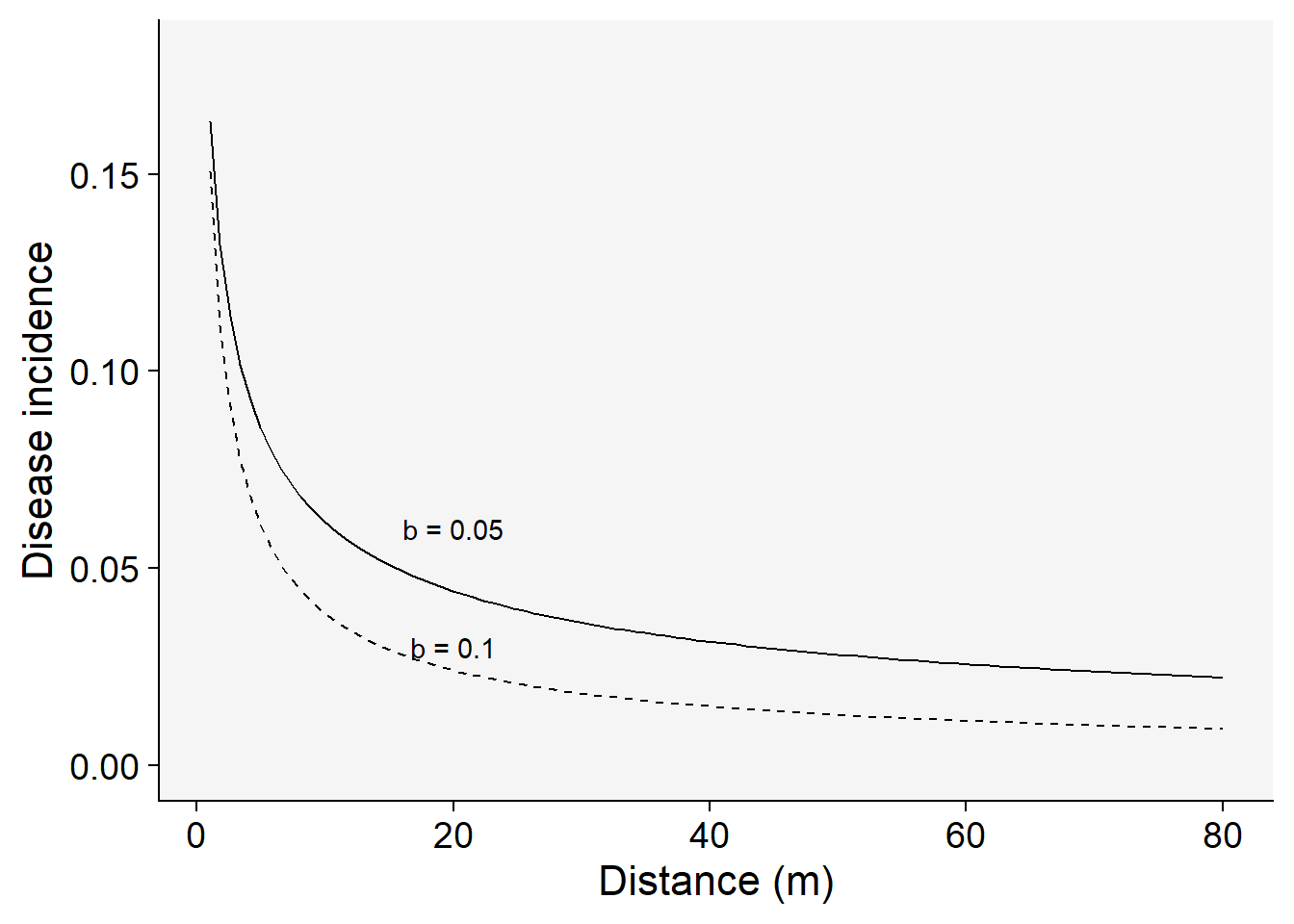
The differential equation of the power law model is given by:
\(\frac{dy}{dx}\) = \(\frac{-b_{P}.Y}{x - C}\)
Similar to the exponential model, \(\frac{dy}{dx}\) is proportional to \(Y\), meaning that the gradient is steeper (more negative) at the highest disease intensity value, usually closer to the source.
14.3 Linearization of the models
14.3.1 Transformations of y
The gradient models, again similar to the temporal disease models, are non linear in their parameters. The model is intrinsically linear if transformations are applied (according to the model) in both sides of the equations. The linear model in its generic state is given by
\(y* = a* + bx\) ,
where the asterisk in \(a\) indicated that one of the transformations was applied in \(y\) that produced the linear model. Note that \(a*\) is the transformed version of the initial disease intensity, which needs to be returned to the original scale according to the respective back-transformation. Follows the linearized form of the two most common gradient models.
\(ln(y) = ln(a_{E}) - b_{E}. x\)
\(ln(y) = ln(a_{P}) - b_{E}. ln(x+C)\)
14.3.2 Plot for the linearized form of models
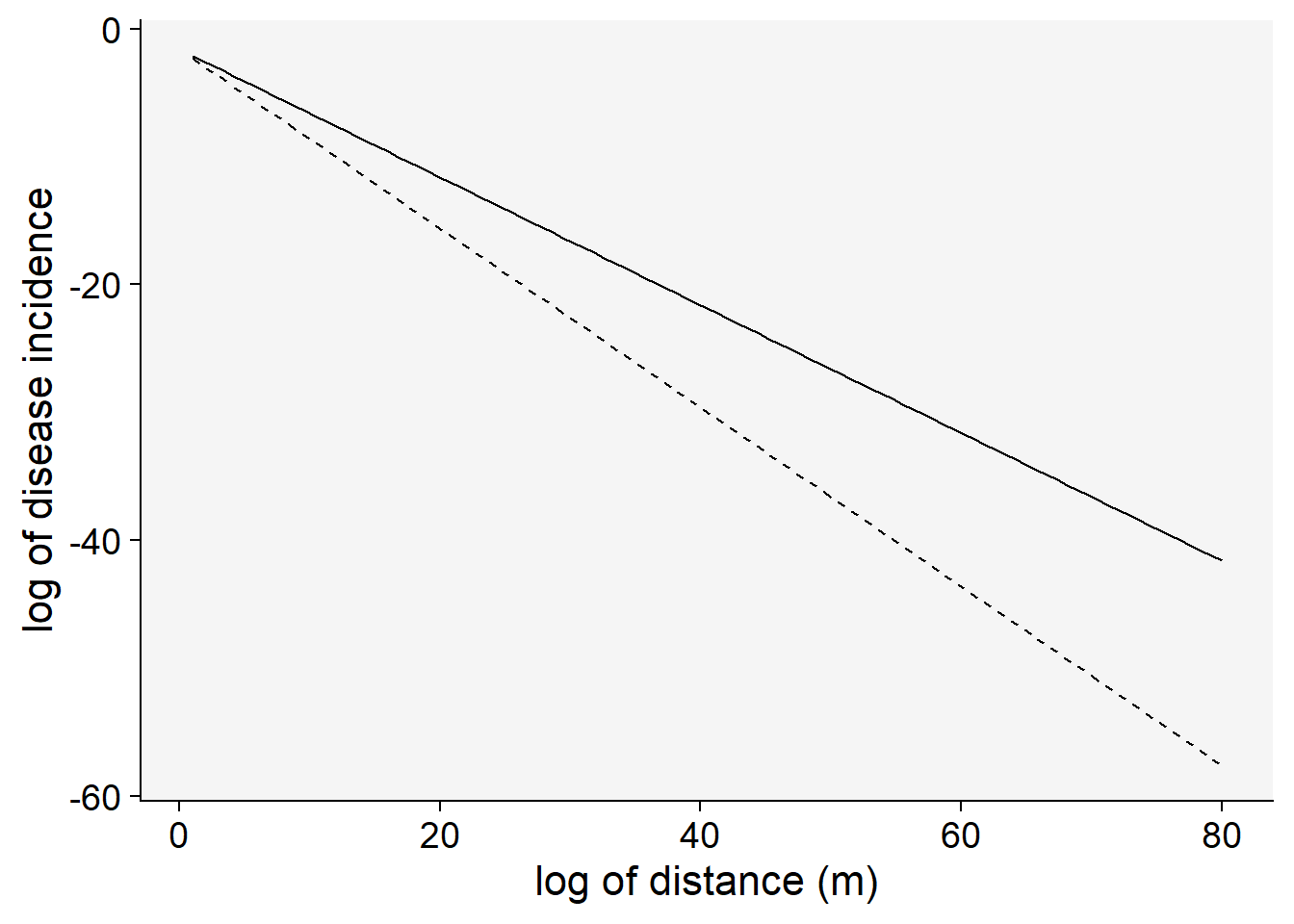
Let’s visualize the linearization of the exponential model with two different slopes (gradient 1 and 2). Note that the transformation used was \(ln(y)\).
C <- 0.5
a1 <- 0.2 # y at zero distance for gradient 1
a2 <- 0.2 # y at zero distance for gradient 2
b1 <- 0.5 # decline rate for gradient 1
b2 <- 0.7 # decline rate for gradient 2
max1 <- 80 # maximum distance for gradient 1
max2 <- 80 # maximum distance for gradient 2
dat2 <- data.frame(x = seq(1:max1), y = seq(0:a1))
dat2 |>
ggplot(aes(x, y)) +
theme_r4pde()+
stat_function(fun = function(x) log(a1) - (b1 * x), linetype = 1) +
stat_function(fun = function(x) log(a2) - (b2 * x), linetype = 2) +
labs(x = "log of distance (m)", y = "log of disease incidence"
)
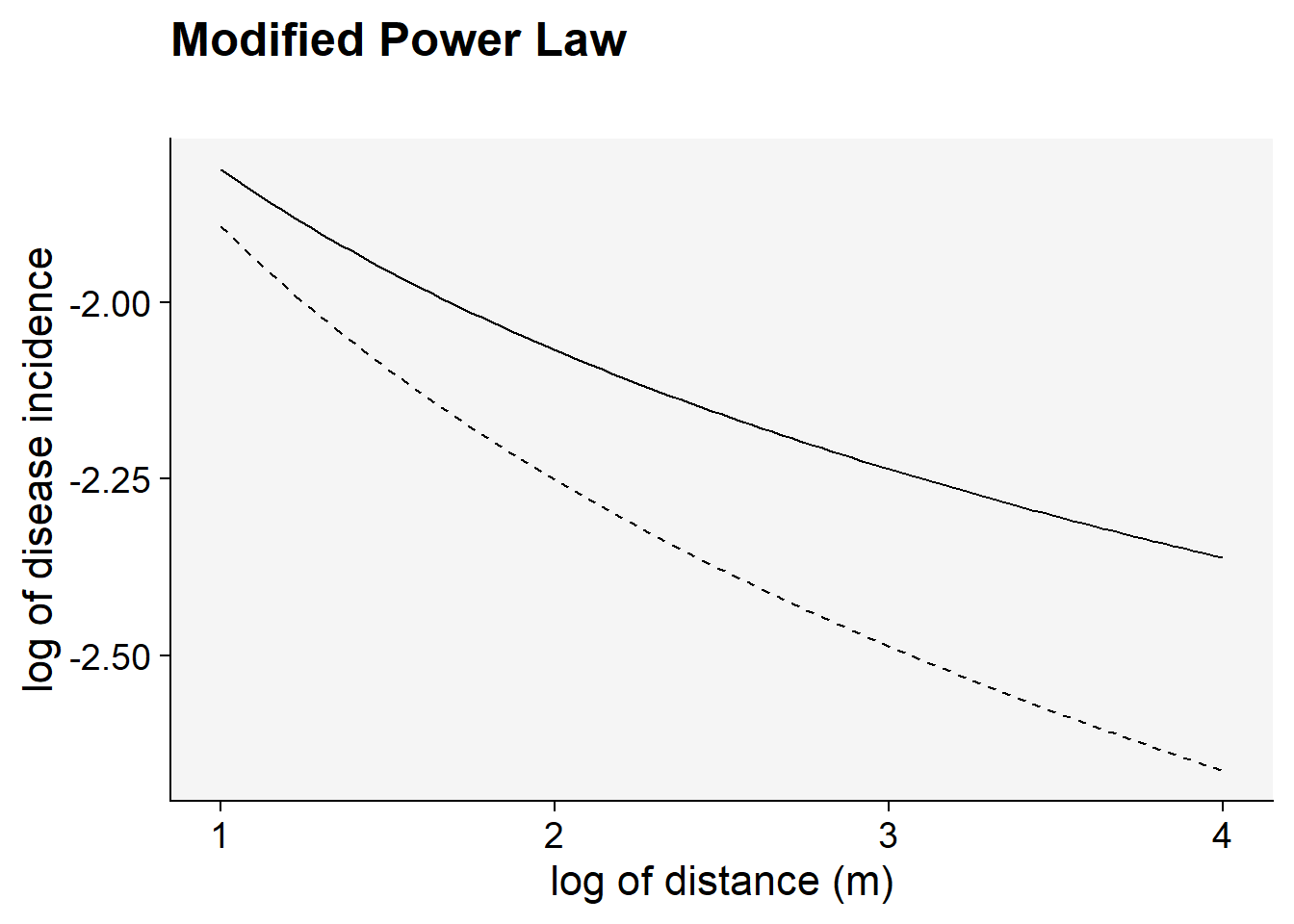
Follows the linearization of the modified power law model. Note that the transformation used was \(ln(y)\) and \(ln(x+C)\) .
C <- 0.5
a1 <- 0.2 # y at zero distance for gradient 1
a2 <- 0.2 # y at zero distance for gradient 2
b1 <- 0.5 # decline rate for gradient 1
b2 <- 0.7 # decline rate for gradient 2
max1 <- log(80) # maximum distance for gradient 1
max2 <- log(80) # maximum distance for gradient 2
dat2 <- data.frame(x = seq(1:max1), y = seq(0:a1))
dat2 |>
ggplot(aes(x, y)) +
theme_r4pde()+
stat_function(fun = function(x) log(a1) - (b1 * log(x + C)), linetype = 1) +
stat_function(fun = function(x) log(a2) - (b2 * log(x + C)), linetype = 2) +
labs(
title = "Modified Power Law",
subtitle = "",
x = "log of distance (m)",
y = "log of disease incidence"
)
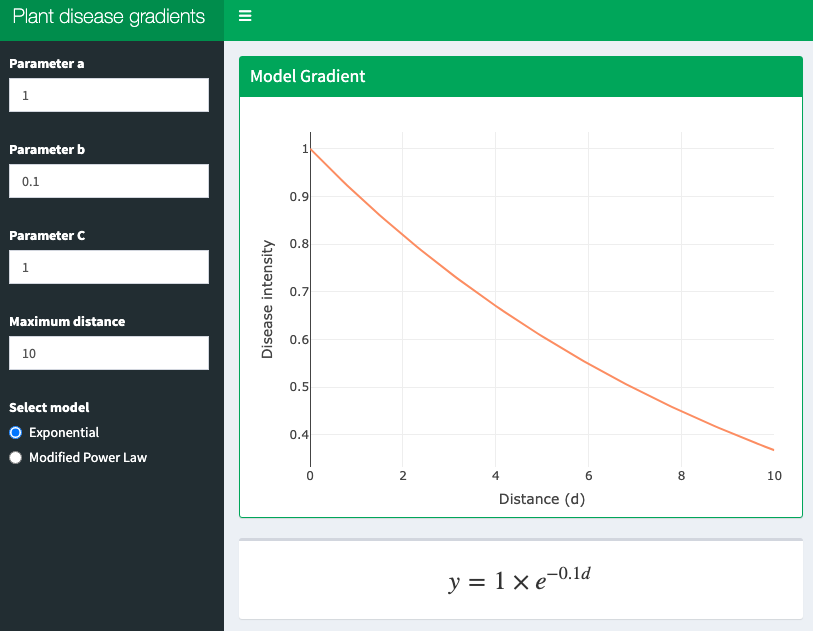
14.4 Interactive application
A shiny app was developed to demonstrate these two models interactively. Click on the image below to get access to the app.